
Introduction
When you walk into a store, everything is intuitively laid out. Products are grouped by category, similar items are displayed together, and featured selections catch your eye, making it easy to find what you need – and even discover things you didn’t know you wanted.
In e-commerce, we aim to recreate that seamless shopping experience online. Using machine learning, we build digital „aisles” for browsing, search engines to help users identify specific products, and recommender systems to create a personalized shopping journey. These tools make online shopping efficient, enjoyable, and engaging.
While search engines let users find exact products, recommender systems add a layer of discovery and personalization. Imagine you’re interested in an instant camera from eMAG and might want to explore options in different colors. If you’ve already purchased it, you might be looking for matching accessories like a travel bag or photo album, or even be reminded to reorder the film packs you frequently buy. Our recommender system understands these needs by analyzing browsing patterns and suggests products that align with each user’s unique interests.
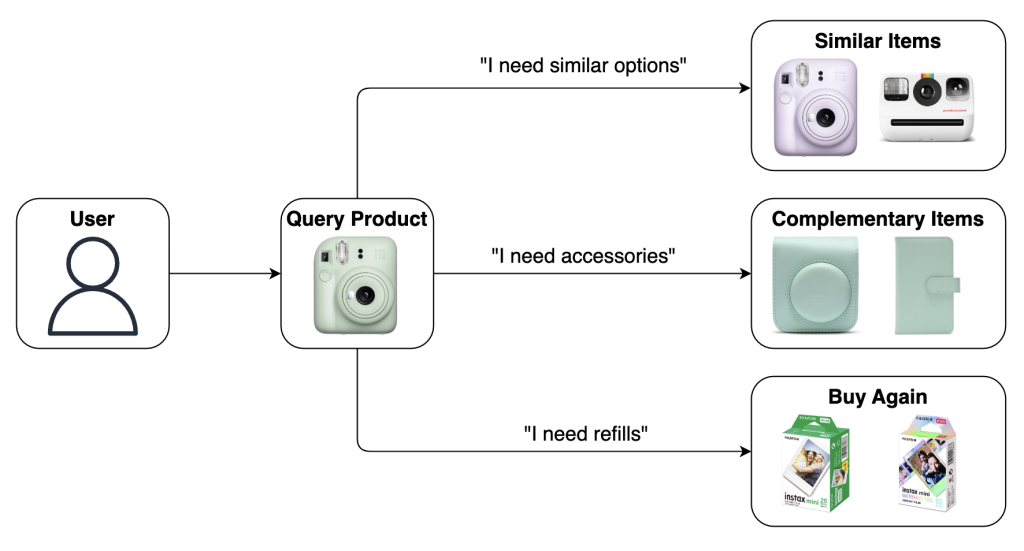
[Examples of user needs]
In this post, we’ll break down the inner workings of eMAG’s recommender system. We’ll share how our team built a neural-based solution that navigates our extensive product catalog, leverages user activity data to anticipate needs, and achieved a significant performance improvement on engagement metrics over previous algorithms.
Balancing Speed and Precision
When discussing recommender systems, we’re not referring to a single model. Instead, a robust system comprises multiple components, each serving a specific role to efficiently deliver relevant recommendations.
Imagine you’re browsing for a LEGO flower-themed building set. As you view one product, our recommender system can efficiently serve a selection of similar flower-themed products.
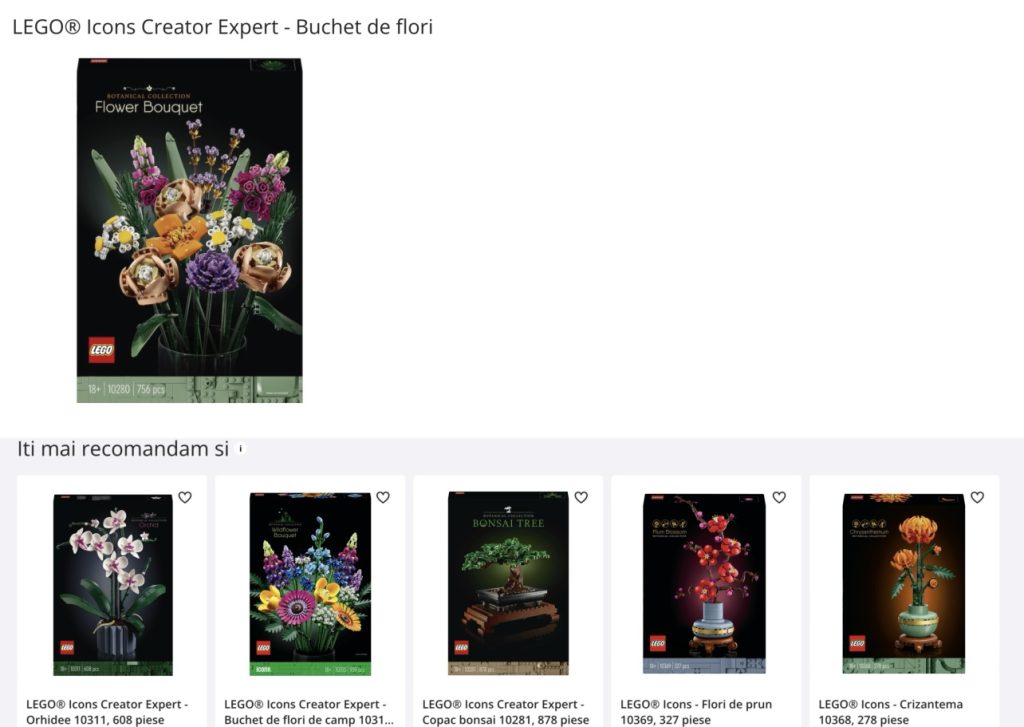
[Example of Recommendations]
Selecting these specific products from eMAG’s vast catalog is anything but simple. With millions of items across diverse categories – from electronics and sports to fashion and cosmetics – finding the most relevant subset can feel like searching for a needle in a haystack.
Nonetheless, the recommendations you see aren’t just chosen randomly; they’re presented in descending order of relevance, with the first item being the most relevant. This ordering is made possible by a ranking model that scores each product for relevance given the user’s interest in a particular item. By assigning relevance scores and sorting products accordingly, we can then display the top suggestions to each user.
Sounds straightforward, right? But here’s the challenge: latency. Users expect recommendations to appear in milliseconds. Scoring millions of products for every request is simply not feasible in real time. So, how do we balance speed with relevance?
Here’s where the concept of a two-stage recommender funnel comes into play, consisting of a candidate generator and a ranking model:
- Candidate Generator (Retrieval): First, we filter out the vast majority of irrelevant products. For instance, if you’re looking at a LEGO set, it’s safe to assume laptops and shampoos won’t be relevant. The candidate generator efficiently retrieves a subset of potentially relevant products—just a few hundred – by using simpler models or even heuristics to quickly filter through the catalog. This stage prioritizes speed over precision.
- Ranking: Next, this smaller, focused subset is passed to the ranking model, which assigns precise relevance scores to each item. Since we’re now dealing with hundreds, not millions, of products, we can afford to use a more complex model, incorporating richer data like product details and previous user behaviour. This allows us to present the most accurate and useful recommendations to the user.
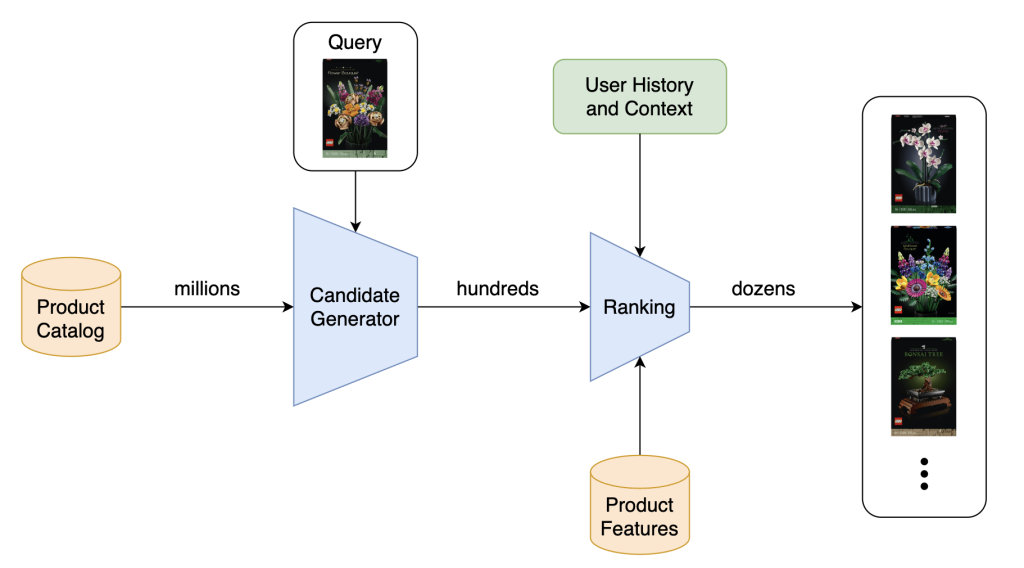
[Recommender System Funnel]
This two-phase approach lets us balance speed and quality. By filtering the vast catalog down to a smaller, relevant pool, we can quickly generate personalized recommendations without sacrificing precision, ultimately enhancing the user’s shopping experience.
Building the Foundation: How the Candidate Generator Curates Relevant Products
At the core of the candidate generator is a product encoder model paired with a nearest neighbour search algorithm. Together, these components create an efficient retrieval system that quickly narrows down relevant products.
The encoder model defines an embedding space where products are represented as high-dimensional vectors. Then, using a nearest neighbour search tool, such as Google’s ScaNN or Facebook’s FAISS, we can identify potential candidate products by measuring the similarity between embeddings.
For the encoder, we have options. We can leverage pre-trained language models like BERT to encode product content (e.g., titles). Alternatively, we can train a prod2vec model on our platform’s interaction data to generate embeddings based on user behavior. We chose prod2vec for its scalability and ability to capture domain-specific product relationships.
For prod2vec we use a siamese (or two-tower) network to embed product IDs and calculate similarity measures between a query product and its candidates. The model minimizes the distance between a query product and its contextually relevant positive candidates while maximizing the distance to randomly generated negative candidates. This setup allows us to extract meaningful product embeddings that reflect real-world user preferences.
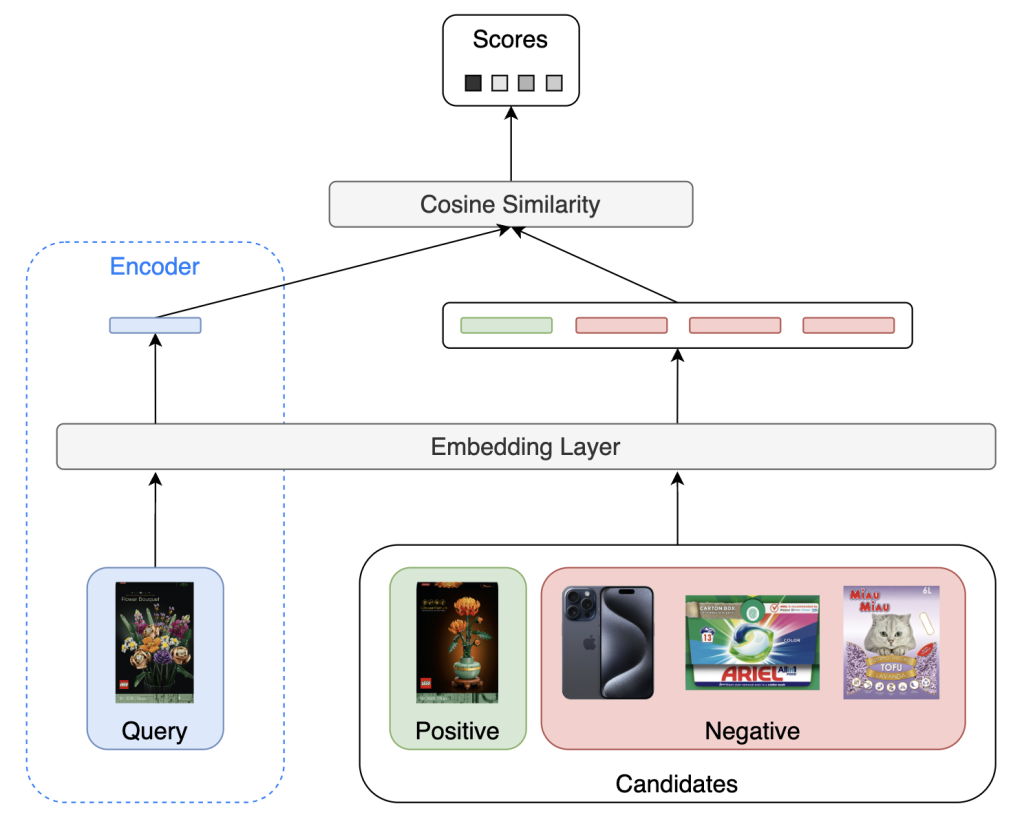
[Siamese Network]
We can extract the query tower and use it as a product encoder for various downstream tasks (e.g., ranking) and to power the candidate generation. While simple, this method captures complex product relationships directly from interaction data.
In the t-SNE plot below, we can see how the product embeddings cluster naturally by category: tech products such as phones, laptops and TVs, cooking-related products and appliances such as deep fryers, cooking pans and stoves, and clothing such as jackets for children, men and women. These clusters emerge solely from user interaction patterns, without relying on explicit product attributes.
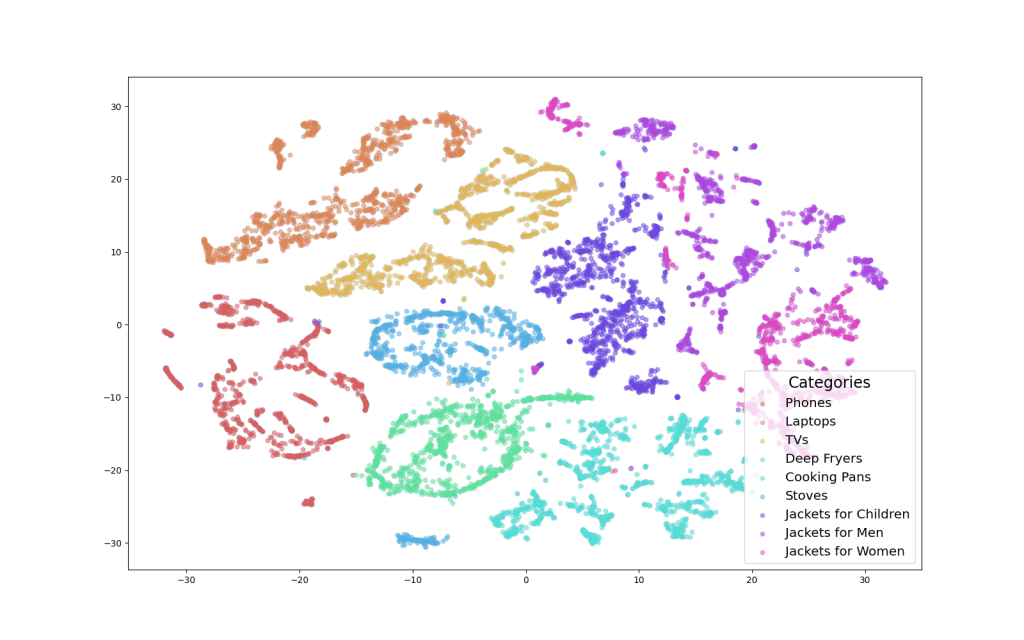
[t-SNE plot]
Personalizing Recommendations: How to Find What Matters Most
The ranking model plays a critical role in personalizing recommendations, ensuring that the displayed products are ordered not just by their relevance to a query product but by their specific relevance to the user.
To achieve this, we model each user as a sequence of their past interactions, intending to predict the likelihood of engagement with candidate products. For training, we build user sessions as time-ordered sequences, where previous items form the interaction history and positive candidates are drawn from future interactions. We also include negative candidates to emulate the diversity of options seen in real-world recommendations.
Many modern ranking models use architectures like YouTube DNN, Wide&Deep or DLRM. At a high level, these models follow a similar structure: they encode and combine input features, then pass them through a feed-forward network (FFN) to output a relevance score.
Our ranking model builds on this standard approach with some key customizations. To better understand its components, we’ll analyze the diagram below.
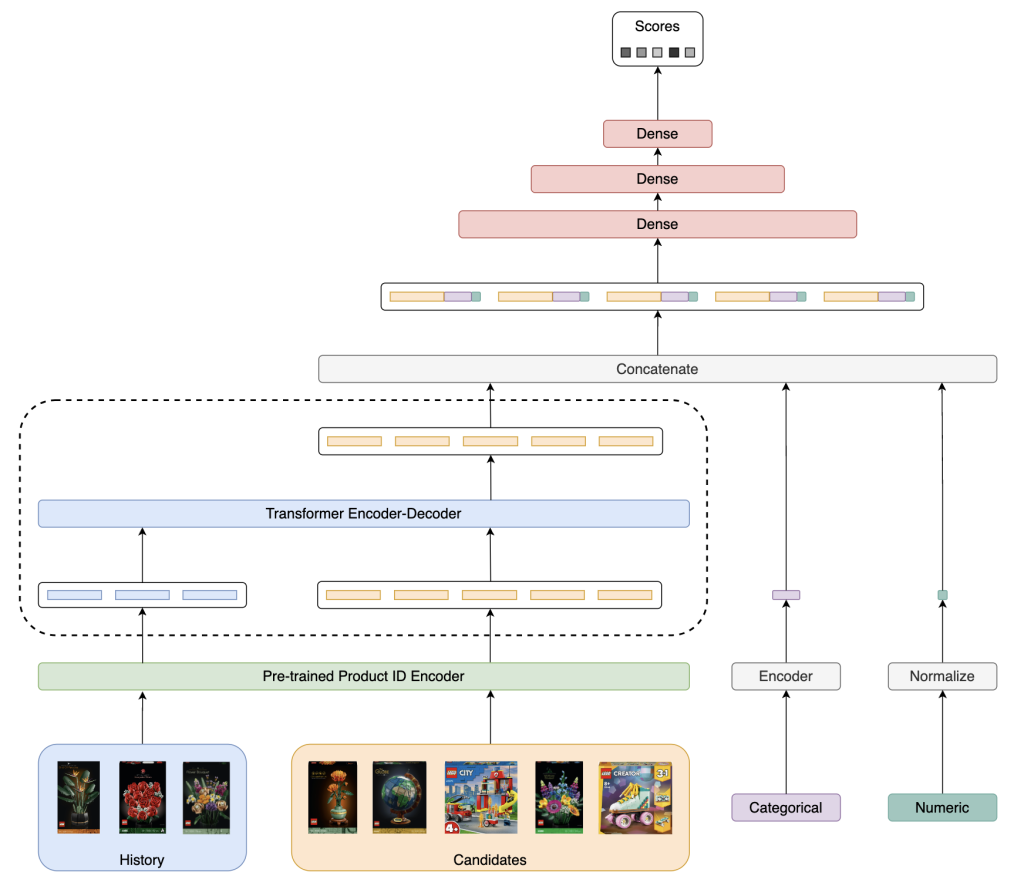
[Ranking Architecture]
The bottom row represents our input features: the interaction history, the list of candidates and any additional relevant features.
Next, depending on their types, we apply different processing and encoding methods. For instance, numeric features are normalized, while categorical features can be encoded either by training an embedding matrix or by fine-tuning a pre-trained matrix, like BERT for product titles.
To embed product IDs, we chose to incorporate the encoder we pre-trained for the candidate generator – shown in green – and further train it alongside the ranking model. This fine-tuning process leverages the product relationships captured from interaction data while significantly speeding up the overall training.
Sequential features, like the interaction history, require specific processing through pooling operations or advanced architectures like LSTM or Transformer Encoders. To capture candidate-history relationships more dynamically, we implemented a Transformer Encoder-Decoder architecture – shown in blue – which is explained further in the following section.
Finally, all processed features are concatenated and passed through several fully connected layers, outputting a score for each candidate.
Transformer Encoder-Decoder: Dynamic Contextual Attention for Ranking
To explore the advantages of the Transformer Encoder-Decoder, we’ll „zoom” into the block highlighted with a dashed line in the diagram.
![]()
[Transformer Encoder-Decoder]
First, we pass the history feature through a Transformer encoder. Instead of reducing the encoded history to a single vector through pooling operations, we feed it, along with the candidate embeddings, to a Transformer decoder.
By leveraging a parallel, non-autoregressive approach, we enable efficient processing of all candidates simultaneously. This allows the model to dynamically focus on relevant parts of the user’s history, improving ranking precision and delivering more relevant recommendations.
Notably, we handle all candidates in a single batch and optimize the order of the entire list instead of scoring each product individually. This list-wise approach is a crucial enhancement, offering a truly personalized user experience.
Evaluation: Measuring Real-World Impact
Now that we’ve built and assembled the recommender system, the crucial question remains: was all the work on these neural networks truly worth it?
As Peter Norvig, Director of Research at Google, wisely stated, „More data beats better algorithms, but better evaluations often beat both.” This highlights the importance of evaluation in machine learning. Without it, neither data nor model improvements guarantee real-world impact. For recommender systems, evaluation is especially challenging, as success isn’t only about how well individual components perform in isolation but how they work together to enhance the user experience.
To ensure our system performs effectively and consistently in a live environment, we rely on a mix of offline metrics and online A/B testing to assess both technical accuracy and practical impact.
- Offline Evaluation with List-wise Metrics: We conduct offline evaluations using a test dataset of users not seen during training, covering a period that extends several days beyond the training window. This approach ensures the model generalizes to new users and behaviors, rather than simply memorizing patterns from the past. We evaluate the model’s ability to rank relevant products using list-wise metrics, such as NDCG and Hit Ratio@k, without affecting live traffic.
- Online Evaluation with A/B Testing: Offline metrics are essential for rapid iteration and validation, but real success in a live environment requires feedback from actual user interactions. Here, A/B testing plays a crucial role. We compare the performance of the new recommender system against the baseline by measuring click-through rate (CTR) and conversion rate. This direct user feedback is invaluable in assessing the real-world impact of the recommender, beyond what we can capture in offline simulations.
Ultimately, our new recommender system achieved a significant increase in online metrics over our previous, non-neural baseline. This improvement reflects not only the technical advancements in our model architecture but also the value of a robust, multi-faceted evaluation strategy that validates impact both offline and online.
Practical Insights: What We Learned Along the Way
As we wrap up, we’d like to share some key insights we gained from building our recommender system:
- Simple Solutions for Simple Problems: Choosing between traditional and neural-based algorithms depends on your needs and data. While implementing neural networks can be exciting, simpler solutions often work better for straightforward problems. Start with a baseline and only add complexity as necessary to meet specific objectives.
- Messy vs Clean: Real-world data is packed with valuable patterns, but it’s also full of noise, outliers, and inconsistencies. While cleaning messy data is crucial, there’s a fine line between improving data quality and over-curating it to the point that it loses the natural variability needed for real-world generalization. We need a balance so the model can handle diverse, unpredictable user behavior in production.
- Negative Candidates: The More, the Merrier: Negative candidates are essential for robust training, as they give the model a contrasting dataset that strengthens generalization. We observed performance gains by increasing both the number and the diversity of negative samples, using strategies like stratified sampling to ensure variation within the candidates.
- Balancing Complexity with Speed: When dealing with real-time recommendations, we’re often balancing accuracy with speed. Even a highly accurate model loses value if it can’t respond within milliseconds. Strive for balance—leverage complexity only as much as the system’s latency constraints allow.
Closing Remarks
Thank you for joining us on this journey of building a recommender system. From efficient candidate generation to personalized ranking, we’ve explored how thoughtful design and technical innovation come together to create impactful solutions.
We hope this glimpse into our approach sparks your curiosity and appreciation for the complexities behind recommendation systems – powering smarter, more seamless experiences every day.


